音声文字起こし(AI) 無料ツール
録音・音声ファイルをAIが自動でテキストに変換。軽量/高精度モードを選択可能。すべての処理はブラウザ内で完結します。
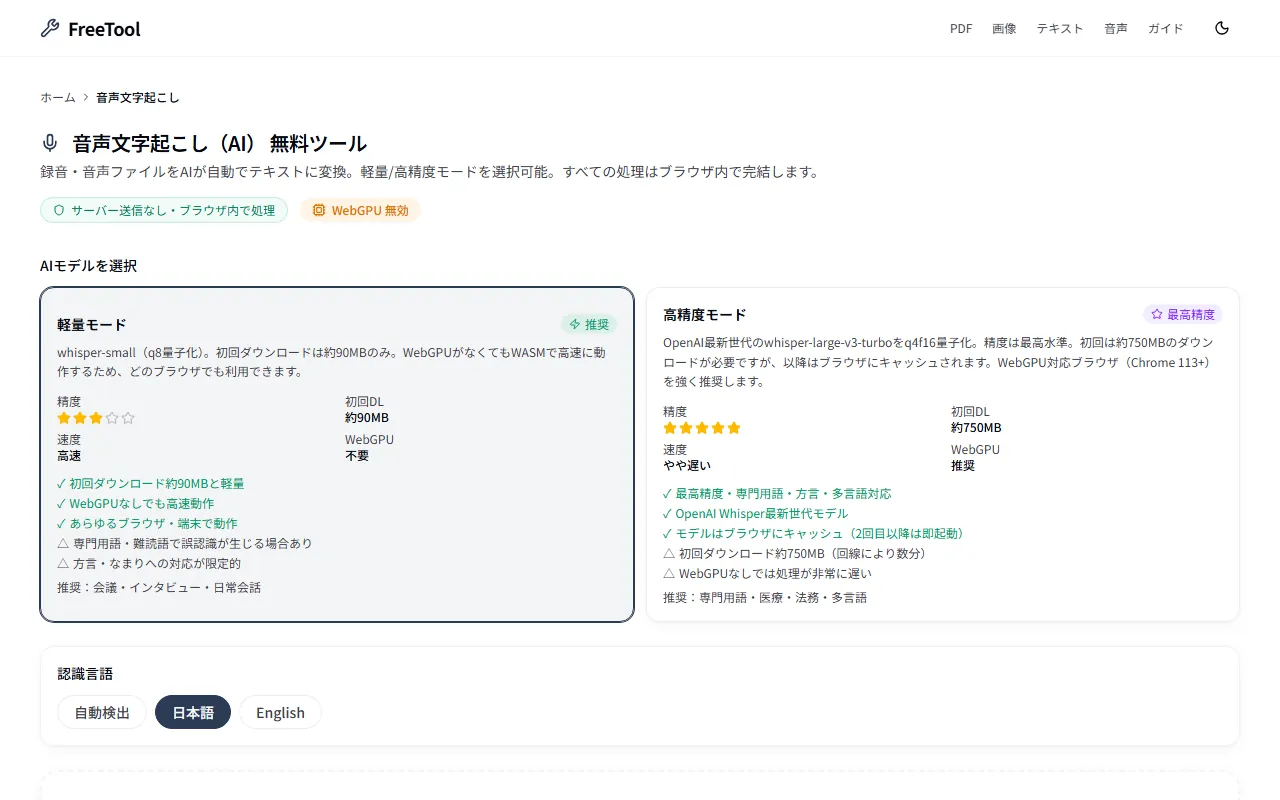
AIモデルを選択
認識言語
音声ファイルをここにドロップ
またはクリックして選択(MP3 / WAV / M4A / WebM / OGG / FLAC)
音声文字起こしとは
音声文字起こしツールは、OpenAIのWhisperモデルをブラウザ内で動作させ、音声ファイルをテキストに変換します。軽量モード(whisper-small)と高精度モード(whisper-large-v3-turbo q4f16)の2種類から用途に合わせて選択可能。FreeToolの音声文字起こしはすべての処理がブラウザ内で完結するため、機密性の高い会議録音や個人情報を含む音声も安心してご利用いただけます。
なぜブラウザ完結が安全なのか
一般的な文字起こしサービスは音声をクラウドサーバーにアップロードして処理します。FreeToolは音声ファイルをサーバーに送信せず、AIモデルをあなたのデバイスで直接実行します。会議の内密な内容や個人情報が外部に漏れる心配がありません。
他のツールとの違い
AudiopenやOtterなどのサービスはサーバーへのアップロードが必須で、有料プランが必要な場合もあります。FreeToolは登録不要・完全無料で、音声データを外部に送信せずに文字起こしを実行できます。
業種・職種別の活用シーン
会議・打ち合わせの議事録作成
社内会議やオンライン商談の録音をAIが自動でテキスト化。録音後すぐにブラウザへドロップするだけで議事録の下書きが完成し、手動での書き起こし時間を大幅に削減できます。音声データがサーバーに送信されないため、社外秘の打ち合わせ録音も安心して処理できます。会議参加者への議事録配布もスピーディに行えます。
メディア・ライターの取材音声テキスト化
インタビュー音声をテキスト化して記事執筆に活用。1時間のインタビューも高精度モード(whisper-large-v3-turbo)なら30〜60分でテキスト化でき、その後の編集・校正作業を大幅に効率化します。取材先のプライバシー保護にもブラウザ完結処理が有効で、音声データが第三者のサーバーに残ることはありません。
医療・介護現場での記録業務
診療録音やケアプラン説明の録音をテキスト化して記録作業の負担を軽減。医療専門用語も高精度モードなら認識率が高く、転記ミスを減らせます。患者の個人情報を含む音声のため、サーバー非送信のブラウザ完結型処理は病院・クリニックの個人情報保護方針に合致します。
教育・研修コンテンツの制作
セミナー・社内研修の録音をテキスト化して資料化。オンライン講義の字幕素材、マニュアル化、eラーニング教材の台本作成に活用できます。大学・ビジネススクール・企業研修部門でのコンテンツ制作効率化に貢献し、録音1本から複数のコンテンツ素材を生み出せます。
ポッドキャスト・動画のトランスクリプト作成
ポッドキャストや動画のトランスクリプト(字幕ファイルの素材)を作成。SEO効果のあるテキストコンテンツとしてブログに掲載したり、YouTubeの字幕ファイルとして活用することで、コンテンツの価値と検索流入を最大化できます。動画1本に対してテキストコンテンツとSEOページを同時に量産できます。
こんな場面で使えます
- 会議・打ち合わせの録音を議事録テキストに変換
- インタビュー音声をテキスト化して記事執筆に活用
- オンライン講義・セミナーの内容をテキストで保存
- ボイスメモの内容をすばやくテキスト化
- 医療・法務の専門的な音声を高精度でテキスト化
- 外国語の音声を文字起こしして翻訳に活用
使い方
音声ファイルをアップロード
モデルと言語を選択
テキストをコピー
トラブルシューティング
モデルのダウンロードが完了しない・途中で止まる
安定した回線でページを再読み込みしてください。高精度モードは約750MBあるため、低速回線では長時間かかります。ダウンロード中はブラウザタブを閉じないでください。ダウンロード完了後はキャッシュされるため2回目以降は即座に起動します。
文字起こしの精度が低い・聞き取れない部分が多い
軽量モード使用中は高精度モード(whisper-large-v3-turbo)に切り替えてください。録音環境のノイズが多い場合は、ノイズリダクション処理後の音声で試すとさらに改善します。マイクと話者の距離を近くして録音すると認識率が向上します。
長い音声ファイルの処理が途中で止まる
1時間以上の長時間音声は30秒チャンクで処理しますが、デバイスのメモリが不足すると止まることがあります。不要なタブを閉じるか、長い音声を30〜60分ごとに分割してから処理してください。
高精度モードが「WebGPU必須」として使えない
Chrome 113以降またはEdge 113以降でWebGPUが利用可能です。アドレスバーに chrome://flags と入力してWebGPUを有効化するか、軽量モード(whisper-small)をご利用ください。
日本語の固有名詞・専門用語が誤認識される
文字起こし後のテキストを手動で修正してください。高精度モードでも固有名詞・業界専門用語の認識には限界があります。音声品質を上げること(雑音を減らし、明瞭に発音した録音)が認識率改善に最も効果的です。
機能比較:FreeTool 音声文字起こし vs Otter.ai
| 機能 | FreeTool | Otter.ai |
|---|---|---|
| 完全無料 | ○ 無制限 | △ 月600分まで無料 |
| 登録不要 | ○ 不要 | × 登録必須 |
| サーバー送信 | なし(ブラウザ完結) | あり(クラウド処理) |
| オフライン動作 | ○(初回ロード後) | × |
| 日本語対応 | ○(whisper) | △ 精度が低い |
| 高精度モード | large-v3-turbo対応 | 独自モデル |